Introduction
In January 2026, Alibaba's Qwen team dropped Qwen3-TTS, an open-source text-to-speech model that's genuinely impressive. If you're looking to understand what makes it tick—from the technical specs to how you'd actually use it—this guide has you covered.

What is Qwen3-TTS?
Think of Qwen3-TTS as a text-to-speech model that actually works across languages. It's open-source (Apache 2.0), trained on 5+ million hours of speech data, and comes in two flavors:
1.7B version: The full-featured model. Better quality, needs more GPU power (6-8GB VRAM)
0.6B version: The lightweight option. Still solid quality, runs on less powerful hardware (4-6GB VRAM)
Both are available on Hugging Face and GitHub. The 1.7B takes up 4.54GB, the 0.6B takes 2.52GB.
Qwen3-TTS Model Specifications and Parameters
Model Variants Comparison
| Aspect | 1.7B Model | 0.6B Model |
|---|
| Parameters | 1.7 billion | 600 million |
| Storage Size | 4.54 GB | 2.52 GB |
| VRAM Required | 6-8 GB | 4-6 GB |
| Performance | Peak quality | Balanced efficiency |
| Use Cases | Production, high-quality | Demo, resource-limited |
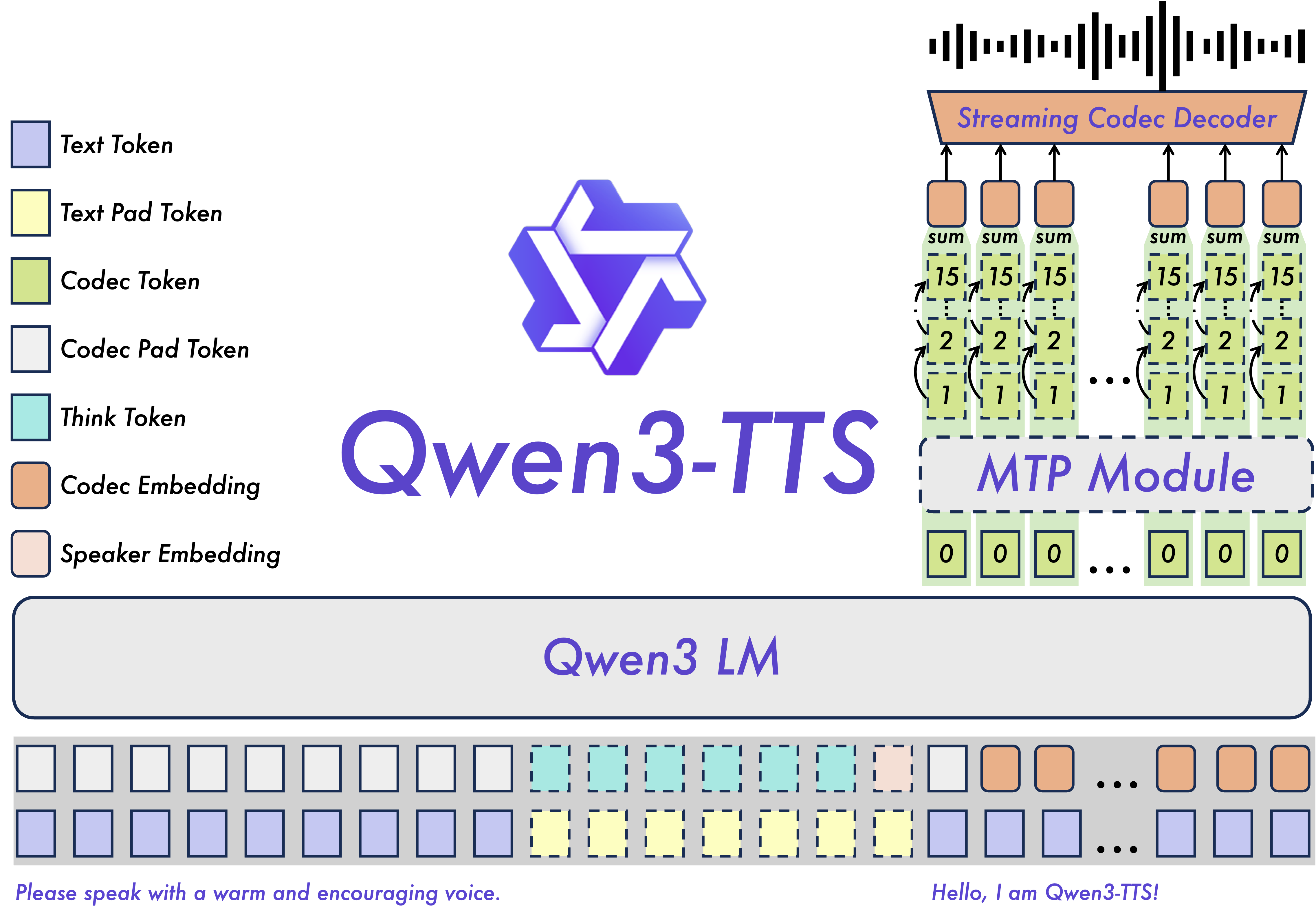
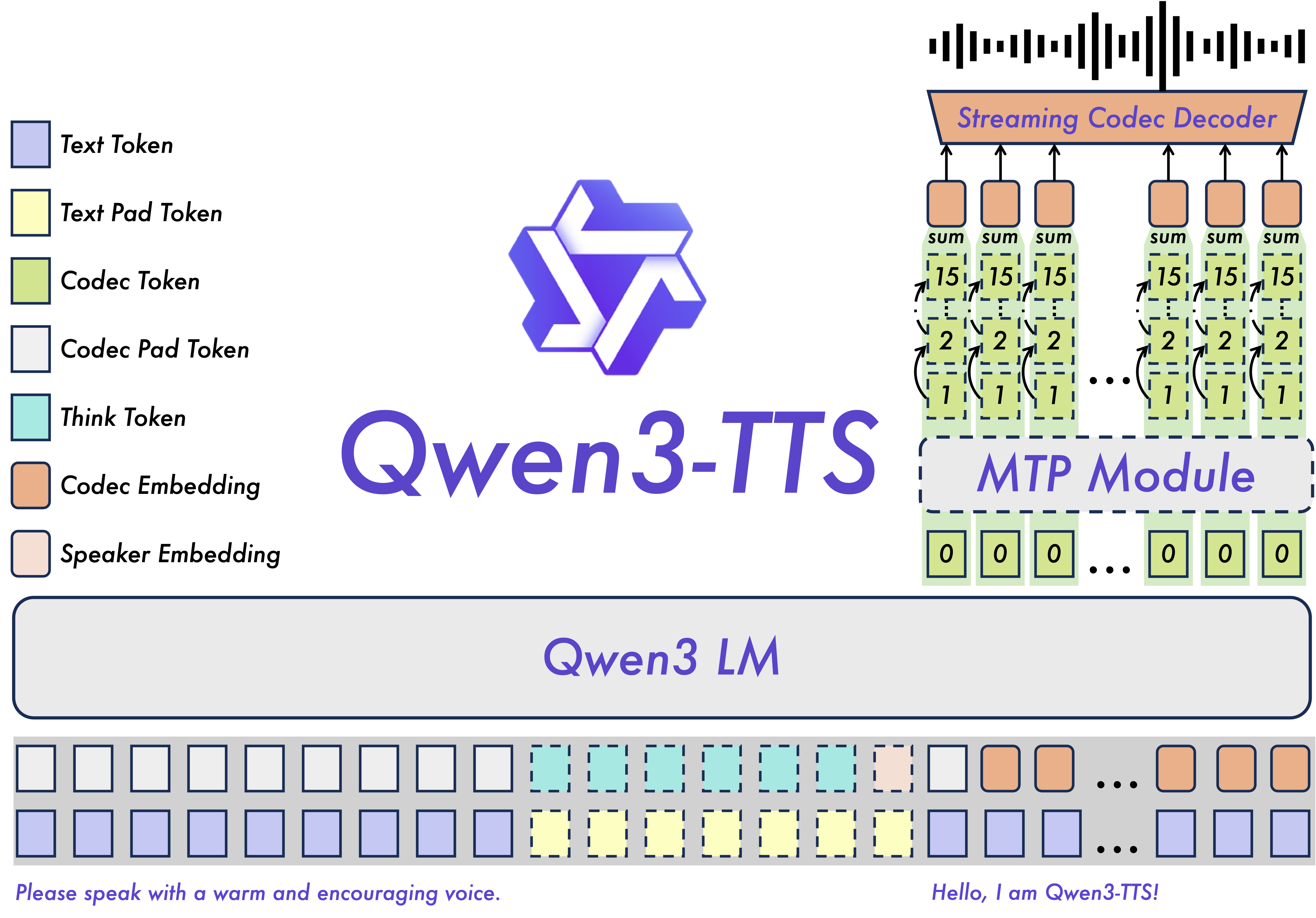
The Secret Sauce: Qwen3-TTS-Tokenizer-12Hz
Under the hood, Qwen3-TTS uses a custom tokenizer that compresses speech without losing the good stuff. Here's how it performs:
STOI: 0.96 (intelligibility is nearly perfect)
UTMOS: 4.16 (sounds natural to human ears)
Speaker Similarity: 0.95 (keeps your voice characteristics)
PESQ Wideband: 3.21
PESQ Narrowband: 3.68
Bottom line: the audio quality is nearly lossless. You're not losing much when the model compresses the speech.
Hardware Requirements for Qwen3-TTS
GPU and VRAM Requirements
For Qwen3-TTS-1.7B Model:
Minimum VRAM: 6 GB
Recommended VRAM: 8 GB
Optimal VRAM: 12+ GB
For Qwen3-TTS-0.6B Model:
Minimum VRAM: 4 GB
Recommended VRAM: 6 GB
Optimal VRAM: 8+ GB
Recommended GPU Hardware
Entry-level: NVIDIA GTX 1070 or equivalent (8 GB VRAM)
Mid-range: NVIDIA RTX 3060 or higher (12 GB VRAM)
Production: NVIDIA RTX 4080 or A100 (16+ GB VRAM)
System Requirements
Python: 3.8 or higher
CUDA: Compatible GPU with CUDA support
Storage: 3-5 GB for model weights
RAM: 16 GB+ system memory recommended
Performance Optimization
To reduce GPU memory usage and improve performance:
FlashAttention 2: Recommended for models loaded in `torch.float16` or `torch.bfloat16`
Quantization: GPTQ-Int8 can reduce memory footprint by 50-70%
Batch Processing: Optimize batch sizes for your hardware
Five Core Features of Qwen3-TTS
1. Voice Design with Natural Language
Create custom voices using natural language descriptions. Specify:
Timbre characteristics: "Deep male voice" or "bright female voice"
Prosody control: "Speak slowly with emphasis" or "Fast-paced energetic delivery"
Emotional tone: "Warm and friendly" or "Professional and authoritative"
Persona attributes: "Young tech enthusiast" or "Experienced narrator"
2. 3-Second Voice Cloning
Qwen3-TTS-VC-Flash supports rapid voice cloning from just 3 seconds of audio input:
Clone any voice for personalized applications
Maintain consistent voice across all content
Create voices for individuals who have lost their speech
Localize content across multiple languages
3. Ultra-Low Latency Streaming
The dual-track hybrid streaming generation architecture enables:
First-packet latency: As low as 97ms
End-to-end synthesis latency: Under 100ms for real-time applications
Ideal for conversational AI, live translation, and interactive voice applications
4. Multilingual Support (10 Languages)
Qwen3-TTS supports 10 major languages with native-like quality:
Chinese (中文) - Mandarin and multiple dialects
English - American, British, and international variants
Japanese (日本語) - Natural prosody and intonation
Korean (한국어) - Accurate pronunciation and rhythm
German (Deutsch) - Precise articulation
French (Français) - Authentic accent and liaison
Russian (Русский) - Complex phonetics handling
Portuguese (Português) - Brazilian and European variants
Spanish (Español) - Latin American and European Spanish
Italian (Italiano) - Regional accent support
5. 49+ High-Quality Voice Timbres
Qwen3-TTS offers over 49 professionally crafted voice timbres:
Gender diversity: Male, female, and neutral voices
Age range: From young adults to elderly speakers
Character profiles: Professional, casual, energetic, calm, authoritative
Emotional range: Happy, sad, angry, neutral, excited
Regional characteristics: Various accents and speaking styles
Qwen3-TTS Performance Benchmarks
Multilingual Word Error Rate (WER)
Qwen3-TTS achieves state-of-the-art performance across multiple languages:
| Language | Qwen3-TTS WER | Performance |
| Average (10 languages) | 1.835% | Best-in-class |
| English | Competitive | Native-level |
| Chinese | Industry-leading | Superior accuracy |
| Italian | Best-in-class | Exceptional |
| French | Superior | Outperforms competitors |
Speaker Similarity Score
Average across 10 languages: 0.789
Outperforms: MiniMax and ElevenLabs
Cross-lingual adaptability: Exceptional
Long-Form Generation Stability
Capable of synthesizing 10+ minutes of natural, fluent speech
No quality degradation over extended audio
Maintains consistent speaker characteristics
Installation and Quick Start
Installation Steps
Start with the basics:
pip install transformers torch
Then clone the repo and install dependencies:
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
pip install -r requirements.txt
Want better performance? Add FlashAttention 2:
pip install -U flash-attn --no-build-isolation
Basic Usage Example
from qwen_tts import Qwen3TTSModel
import soundfile as sf
# Load the model
model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice")
# Generate speech with custom voice
wavs, sr = model.generate_custom_voice(
text="Hello, this is Qwen3-TTS speaking.",
language="English",
speaker="Ryan"
)
# Save the audio
sf.write("output.wav", wavs[0], sr)
Voice Cloning Example
from qwen_tts import Qwen3TTSModel
# Load the base model for voice cloning
model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-Base")
# Clone voice from 3-second audio sample
wavs, sr = model.generate_voice_clone(
text="Your text here",
voice_sample_path="voice_sample.wav",
language="English"
)
Real-World Applications of Qwen3-TTS
Content Creation and Media Production
Audiobook narration: Multiple voices for character dialogue
Podcast production: Consistent voice across episodes
Video voiceovers: Multilingual content localization
E-learning: Engaging educational content in multiple languages
Conversational AI and Virtual Assistants
Customer service bots: Natural-sounding automated support
Voice assistants: Personalized voice interactions
Interactive IVR systems: Enhanced caller experience
Smart home devices: Multilingual voice control
Accessibility Solutions
Screen readers: Enhanced accessibility for visually impaired users
Communication aids: Voice restoration for speech-impaired individuals
Language learning: Pronunciation practice with native-like voices
Translation services: Real-time multilingual translation with natural voices
Gaming and Entertainment
Character voices: Dynamic NPC dialogue generation
Interactive storytelling: Adaptive narrative experiences
Virtual influencers: Consistent brand voice across platforms
Metaverse applications: Realistic avatar voices
Qwen3-TTS vs Competitors
Comprehensive Comparison
| Feature | Qwen3-TTS | GPT-4o Audio | ElevenLabs |
| Open Source | ✅ Apache 2.0 | ❌ Proprietary | ❌ Proprietary |
| Languages | 10 major languages | Multilingual | 5000+ voices |
| Voice Timbres | 49+ voices | Multiple voices | 5000+ voices |
| Voice Cloning | 3-second rapid clone | Available | High-quality cloning |
| First-Packet Latency | 97ms | Low | Varies |
| WER Performance | State-of-the-art | Competitive | Good |
| Pricing | Free (self-hosted) | $0.015/min | Premium pricing |
| Emotional Control | Natural language instructions | Emotional control features | Unparalleled depth |
Key Advantages of Qwen3-TTS
1. Cost-Effectiveness
Open-source model eliminates licensing fees
Self-hosting option for complete cost control
API pricing competitive with commercial alternatives
2. Multilingual Excellence
Superior WER scores across multiple languages
Extensive Chinese dialect support unmatched by competitors
Natural code-switching for multilingual content
3. Customization Freedom
Full model access for fine-tuning
Voice cloning without restrictions
Integration flexibility for custom applications
4. Low Latency Performance
97ms first-packet latency for real-time applications
Streaming generation for interactive experiences
Optimized for conversational AI use cases
Common Questions About Qwen3-TTS
Can I use Qwen3-TTS commercially?
Yes! Qwen3-TTS is released under the Apache 2.0 license, which permits commercial use. You can use it for commercial applications without licensing fees.
What's the difference between 1.7B and 0.6B models?
The 1.7B model offers peak performance and quality, while the 0.6B model is more lightweight and suitable for resource-constrained environments. Choose based on your hardware capabilities and quality requirements.
How much VRAM do I need?
0.6B model: 4-6 GB VRAM minimum
1.7B model: 6-8 GB VRAM minimum
Recommended: 12+ GB for optimal performance
Can I fine-tune Qwen3-TTS?
Yes, the open-source nature of Qwen3-TTS allows for fine-tuning on custom datasets. This enables you to create specialized models for specific use cases or languages.
Conclusion
Qwen3-TTS represents a significant milestone in open-source text-to-speech technology. With its superior multilingual performance, extensive voice options, ultra-low latency, and powerful voice cloning capabilities, it offers a compelling alternative to proprietary solutions.
The model's open-source nature under the Apache 2.0 license democratizes access to state-of-the-art TTS technology, enabling developers, researchers, and businesses to build innovative voice applications without licensing constraints.
Whether you're creating audiobooks, building conversational AI, or developing accessibility solutions, Qwen3-TTS provides the tools and flexibility needed for success in 2026 and beyond.
Resources and Links
Official Blog: Qwen3-TTS Announcement
GitHub Repository: QwenLM/Qwen3-TTS
Hugging Face Models: Qwen/Qwen3-TTS-12Hz-1.7B-Base
Documentation: Qwen AI Documentation
Community: Qwen Discord and GitHub Discussions
Link
Z-Image: Free AI Image Generator
Z-Image-Turbo: Free AI Image Generator
Free Sora Watermark Remover
Zimage.run Google Site
Zhi Hu
Twitter
LTX-2
*Keywords: Qwen3-TTS, text-to-speech, TTS model, open-source TTS, multilingual TTS, voice cloning, AI voice synthesis, speech synthesis, Qwen AI, voice generation, natural language processing, conversational AI, voice assistant, TTS hardware requirements, voice design, streaming TTS*