Introduction: A New Milestone in Document Parsing
In today's rapidly evolving AI landscape, document parsing technology has become a critical bridge connecting the physical and digital worlds. From academic papers to business contracts, from invoices to historical archives, massive volumes of document information urgently need to be accurately and efficiently digitized and structured. This goes beyond simple OCR (Optical Character Recognition) upgrades—it represents a comprehensive understanding of documents' deep semantics and structure.

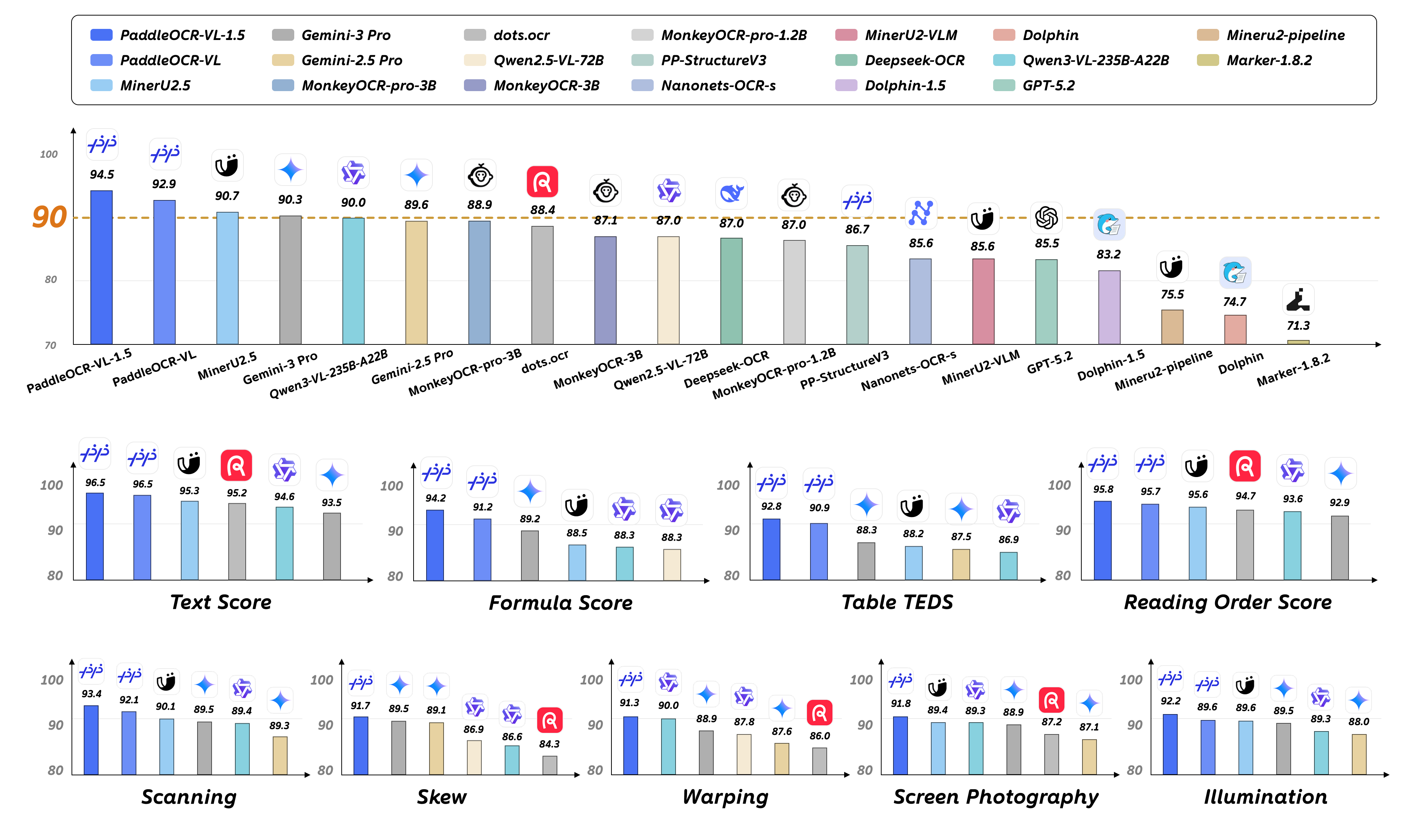
On January 29, 2026, Baidu's PaddlePaddle team released PaddleOCR-VL-1.5, a multi-task Vision-Language Model (VLM) with only 0.9B (900 million) parameters that achieved 94.5% accuracy on the OmniDocBench v1.5 benchmark, setting a new State-of-the-Art (SOTA) record. Even more remarkably, this lightweight model outperformed massive general-purpose VLMs like Qwen3-VL-235B and Gemini-3 Pro in real-world robustness testing.
PaddleOCR-VL-1.5 represents more than just a performance improvement—it marks a paradigm shift in document parsing technology: from single text recognition to unified parsing of tables, formulas, charts, and seals; from recognition in ideal conditions to handling real-world challenges like scanning, skewing, warping, and screen photography. This marks the official entry of document parsing technology into a new era of "practicality" and "intelligence."
Core Highlights
1. Ultra-Lightweight Architecture with SOTA Performance
The most striking feature of PaddleOCR-VL-1.5 is its extreme parameter efficiency. With just 0.9B parameters, it achieves 94.5% accuracy on OmniDocBench v1.5, surpassing not only its predecessor PaddleOCR-VL-1.0 but also demonstrating remarkable advantages in comparisons with large general-purpose VLMs:
vs. Qwen3-VL-235B: Only 1/260 of the parameter size, yet superior performance on document parsing tasks
vs. Gemini-3 Pro: More stable performance in real-world scenario testing
vs. Specialized Models: Significant improvements in table, formula, and text recognition
This parameter efficiency stems from PaddlePaddle team's deep understanding and careful design of document parsing tasks. The model employs a NaViT-style dynamic resolution visual encoder paired with the lightweight ERNIE-4.5-0.3B language model, maintaining high accuracy while dramatically reducing computational costs and deployment barriers.
2. Six Core Capabilities in a Unified Model
PaddleOCR-VL-1.5 is a true multi-task model, supporting six core capabilities within a single architecture:
OCR (Text Recognition): Supports 100+ languages, with new support for Tibetan and Bengali scripts, optimized for rare characters, ancient texts, and text decorations (underlines, emphasis marks)
Table Recognition: Supports complex table structures, including automatic cross-page table merging, multilingual tables, and wireless tables
Formula Recognition: Supports LaTeX format output, specially optimized for physical distortions like scanning, warping, and screen photography
Chart Recognition: Understands and extracts data and trends from charts
Seal Recognition (New): Recognizes official seals and stamps, handling challenges like curved text, blurred images, and background interference
Text Spotting (New): Supports precise text line localization and recognition, using 4-point quadrilateral representation to adapt to rotated and skewed layouts
This unified multi-task architecture not only simplifies deployment but, more importantly, enables knowledge sharing and collaborative optimization across different tasks, achieving better performance on each task.
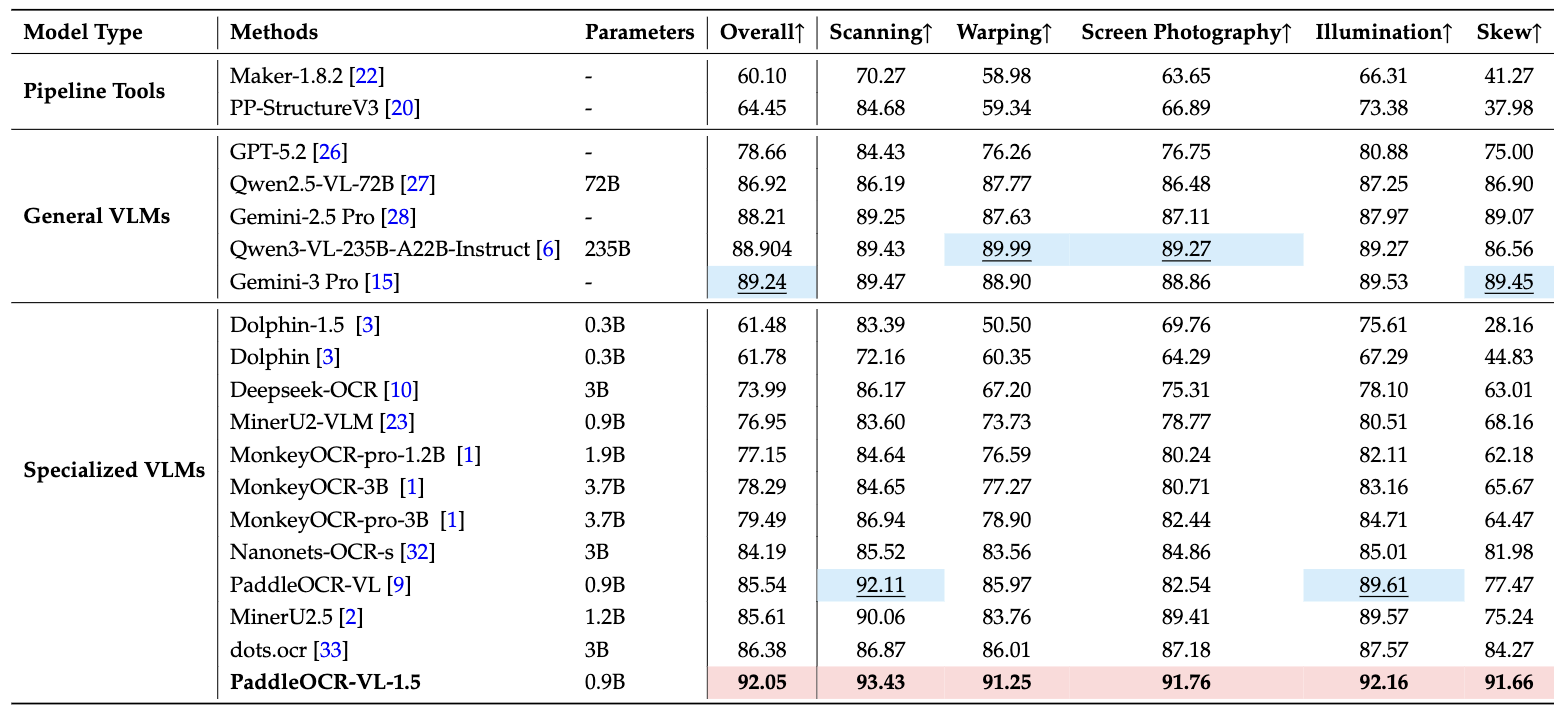
3. Real-World Robustness: Real5-OmniDocBench
To evaluate the model's performance in real-world scenarios, the PaddlePaddle team constructed the Real5-OmniDocBench benchmark, covering five common physical distortion scenarios:
Scanning: Noise and moiré patterns from scanners
Skew: Documents photographed at incorrect angles
Warping: Non-planar deformations from paper folding and bending
Screen Photography: Capturing content displayed on screens
Illumination: Uneven lighting and shadows
On this more practical test set, PaddleOCR-VL-1.5 achieved an overall accuracy of 92.05%, setting a new SOTA record. This means the model maintains stable high performance whether processing contract photos taken with a smartphone or historical documents processed by scanners.
Technical Architecture Deep Dive
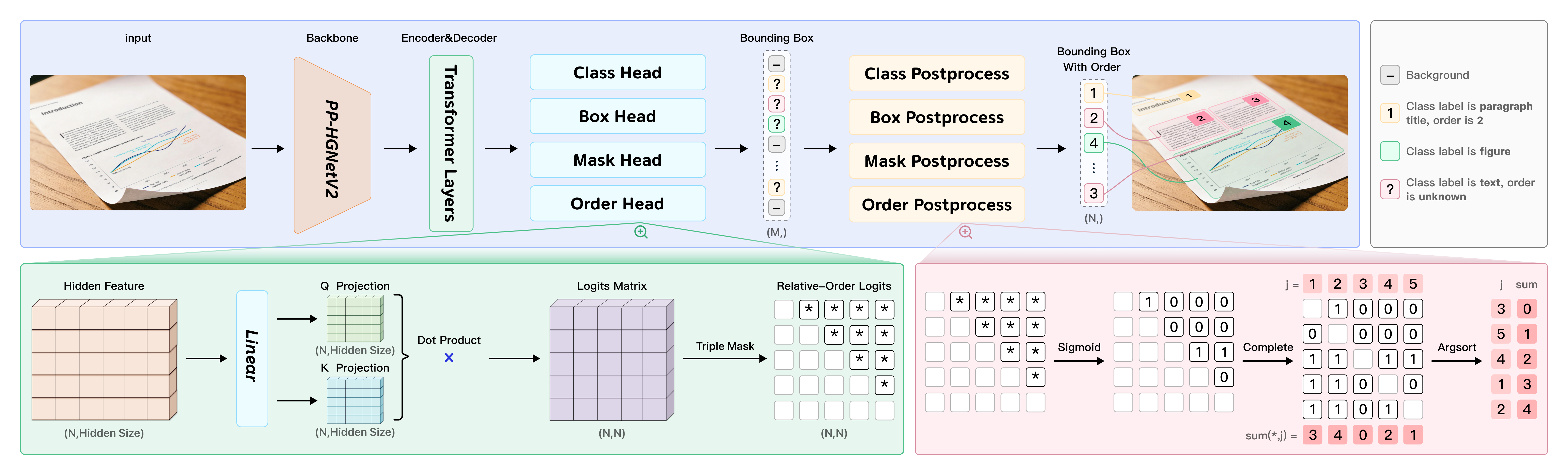
PaddleOCR-VL-1.5 adopts an innovative two-stage architecture design that organically combines layout analysis and element recognition for end-to-end document parsing capabilities.
PP-DocLayoutV3: Unified Layout Analysis Engine
PP-DocLayoutV3 is the first stage of PaddleOCR-VL-1.5, responsible for document layout analysis. Unlike traditional rectangular detection boxes, PP-DocLayoutV3 introduces instance segmentation technology to predict precise pixel-level masks, crucial for handling skewed and warped documents.
Core Innovations:
Multi-Point Localization: Supports quadrilateral or even polygonal bounding box prediction instead of traditional two-point rectangles, enabling accurate framing of skewed and rotated document elements.
Unified Reading Order Prediction: Integrates reading order prediction directly into the Transformer decoder through a Global Pointer Mechanism to compute precedence relationships between elements, eliminating cascading errors in traditional methods.
Instance Segmentation Capability: Based on the RT-DETR object detector, PP-DocLayoutV3 uses mask-based detection heads to predict precise pixel-level masks, effectively isolating document components in non-ideal scenarios.
PaddleOCR-VL-1.5-0.9B: Element-Level Recognition Model
The second stage, PaddleOCR-VL-1.5-0.9B, performs fine-grained recognition on elements obtained from layout analysis. The model inherits the lightweight architecture of PaddleOCR-VL-0.9B but with significantly expanded capabilities.
Architecture Components:
Visual Encoder: Uses a NaViT-style dynamic resolution encoder, supporting maximum resolutions of 1280×28×28 (document parsing) and 2048×28×28 (text spotting)
Adaptive MLP Connector: Maps visual features to the language model's input space for effective vision-language alignment
Language Model: Uses the lightweight ERNIE-4.5-0.3B as the language backbone, a large-scale pre-trained Chinese language model with strong semantic understanding
Training Strategy: Progressive training paradigm with three stages - pre-training (46M image-text pairs), post-training (5.6M instruction data), and reinforcement learning (GRPO optimization).
Performance Evaluation & Comparison
OmniDocBench v1.5: Comprehensive Leadership
OmniDocBench v1.5 is one of the most authoritative document parsing benchmarks, covering multiple element types including text, tables, formulas, and charts. PaddleOCR-VL-1.5 achieved 94.5% overall accuracy, setting new SOTA records across multiple sub-tasks:
Overall Accuracy: 94.5% (surpassing all open-source and closed-source models)
Table Recognition: Significant improvements, especially on complex and cross-page tables
Formula Recognition: Substantially improved LaTeX format output quality
Text Recognition: Excellent performance on rare characters, ancient texts, and text decorations
Reading Order: End-to-end prediction accuracy reaches new heights
Comparison with Competitors:
| Model | Parameters | OmniDocBench v1.5 | Features |
|---|
| PaddleOCR-VL-1.5 | 0.9B | 94.5% | Lightweight, SOTA |
| Qwen3-VL-235B | 235B | 93.8% | General-purpose LLM |
| Gemini-3 Pro | Undisclosed | 92.1% | Closed-source commercial |
| DeepSeek-OCR | Undisclosed | 91.5% | Optical 2D mapping |
| MonkeyOCR v1.5 | Undisclosed | 90.2% | Three-stage framework |
Real5-OmniDocBench: Real-World Performance
On Real5-OmniDocBench testing, PaddleOCR-VL-1.5 demonstrated exceptional robustness with an overall accuracy of 92.05%, surpassing all tested models including general-purpose VLMs with far larger parameter sizes.
Hardware Requirements & Deployment
Hardware Requirements
Recommended Configuration:
GPU: NVIDIA A100, AMD Instinct MI series
VRAM: 8GB+ (16GB+ recommended for larger batches)
CPU: 8+ cores
RAM: 16GB+
Minimum Configuration:
GPU: NVIDIA RTX 3060 or equivalent
VRAM: 6GB+
CPU: 4+ cores
RAM: 8GB+
Supported Platforms: CUDA (NVIDIA GPU), ROCm (AMD GPU, Day 0 support), CPU inference
Deployment Options
1. Docker Deployment (Recommended)
docker run --rm --gpus all --network host \
paddlepaddle/paddleocr-genai-vllm-server:latest-nvidia-gpu \
paddleocr genai_server --model_name PaddleOCR-VL-1.5-0.9B
2. vLLM Accelerated Deployment
vllm serve PaddlePaddle/PaddleOCR-VL-1.5-0.9B \
--host 0.0.0.0 --port 8080
3. Native PaddlePaddle Deployment
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("document.pdf")
Use Cases & Best Practices
Typical Application Scenarios
Document Digitization: Convert paper documents and scans to editable digital formats
RAG System Preprocessing: Provide high-quality structured document data for LLMs
Invoice/Contract Recognition: Automatically extract key information from invoices and contracts
Academic Paper Parsing: Extract text, formulas, tables, and charts from papers
Multilingual Document Processing: Support 100+ languages
Seal Recognition: Recognize seals on official documents
Scene Text Recognition: Recognize text in billboards, signs, and posters
Best Practice Recommendations
Choose Appropriate Deployment: Use vLLM for production, Docker for development
Optimize Input Resolution: Adjust based on document type
Batch Processing: Use batching for large volumes to improve throughput
Result Post-processing: Utilize structured output for cross-page table merging
Error Handling: Adjust preprocessing parameters for failed recognitions
Conclusion
PaddleOCR-VL-1.5 represents a significant breakthrough in document parsing technology. With only 0.9B parameters, it achieves 94.5% SOTA accuracy and outperforms much larger general-purpose models in real-world robustness testing.
Core Advantages:
Parameter Efficiency: Minimal parameters, low deployment cost
Multi-Task Unified: Six core capabilities in one model
Real-World Robust: Handles scanning, skewing, warping scenarios
Open Source: Apache 2.0 license, fully open-source
Related Links:
Official Website: https://www.paddleocr.com
GitHub Repository: https://github.com/PaddlePaddle/PaddleOCR
HuggingFace Model: https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
Technical Paper: https://arxiv.org/abs/2601.21957
Link
Z-Image: Free AI Image Generator
Z-Image-Turbo: Free AI Image Generator
Free Sora Watermark Remover
Zimage.run Google Site
Zhi Hu
Twitter
LTX-2